The Low-Latency Pipeline
General information on online |
|
Some figures explaining the various steps |
|
Infrastructure of the involved directory |
|
List of parameters in the configuration file |
|
How to run |
|
Page overview |
General information
The online is structured in the following way:
perform a zero-lag analysis on available frames which are located in the RAM memory, send to lumin the triggers with a certain significance
collects zero-lag triggers, produce results page, produce CED for significant triggers
performing background analysis with a greater latency
…
Differing from the rest of the infrastructure, the online scripts are python based. There is a general configuration file cWB_conf.py which contains all the information, then there are various cWB-like configuration files for:
user_parameters.C: zero lag
user_parameters_bkg.C: background
user_parameters_pe.C: parameter estimation
…
N.B. the name of these files are put in cWB_conf.py. Even if it should be safe to change them, we do not suggest to do.
Directory structure
Below we show the directory structure for the default value. Each time we use the cwb_online command two directories are created:
Main directory (with the name chosen in the configuration file, see Configuration file
WWW directory (WWW/LSC/online on ATLAS or public_html/online on CIT)

Online Configuration file
The general configuration file should be called cWB_conf.py and put in the RUN_cWB directory. It contains a list of the following parameters:
General setup
Where to find frames, involved detectors, working directory
title: A title for the web pages
label: working name of the directory
online_dir: path of working dir
frames_dir: directory of the frames saved in RAM, used for zero lag
bkg_dir: directory for frames saved permanently, used for background analysis
bkg_fnames: pre-fix of file names, used for background
ifos: involved interferometers
channelname: Channel name in the frames containing h(t)
debug: level of debugging
Zero lag setup
job_offset: scratch for job selection
job_timeout:
min_seg_duration: minimum segment duration for zero lag
seg_duration: typical segment duration for zero lag
look_back: search for frames at time before the official start
sleep: pause during the creation of segments
max_jobs:
science_segment_offset=[]/moving_step: possibility to perform more analyses shifted of the values specified here.
run_start: starting time, if set to -1 or not defined: it is the local time
run_stop:: stop time, if set to -1 or not defined: it is never ending
cwb_par: list of parameters written in C++ code that are common for all cWB user_parameters files (zero lag, bkg)
Background setup
log_path: path where to put log files of condor submission (depend on cluster)
bkg_delay: time to wait from last available segment to start job submission
bkg_nlags: number of lags (not accounting superlags)
bkg_split: number of jobs in which splitting the total nlags
bkg_job_duration: typical and maximum job lenght
bkg_job_duration: minimum job lenght
bkg_njobs: number of super-lags
bkg_framesize: frame length
accounting_group: tag for condor submission
condor_requirements: requirements for condor machine selection
Plugins
qveto_plugin: Path of plugin used for Qveto definition. The Plugin is copied inside the run_dir/config directory. After the creation of the all dir the code asks to compile it.
pe_plugin: Path of plugin used for Parameter estimation. The Plugin is copied inside the run_dir/config directory. After the creation of the all dir the code asks to compile it.
Directories
These directories follows the general structure, we suggest not to modify them
run_dir: contains zero lag script
jobs_dir: contains zero lag job
seg_dir: contains segments list
segs1: files containing total segment list
zerolag_par: cWB user_parameters for zero lag
bkg_par: cWB user_parameters for background
pe_par: cWB user_parameters for Parameter estimation
bkg_run_dir: contains background script
bkg_postprod_dir: contains figure of merit script for background
bkg_job_dir: contains background jobs
bkg_segments_dir: contains background segments list, i.e. the following files:
bkg_considered_segments_file
bkg_processed_segments_file
bkg_running_segments_file
bkg_missing_segments_file
bkg_run_segments_file
bkg_job_segments_file
web_dir: local directory where to put web pages (depend on cluster)
web_link: web pages link (depend on cluster)
Data quality
If Data Quality are provided
DQ_Channel=[]: channel inserted in the frames to value if the data are good or not
DQ_channel_samples=[]: lenght of frames
bitmask=[]: information contained in the frames for good times to be analyzed
E-mails
List of e-mails to advertize in case of triggers
emails=[“”,””,..]
phone_mail: mail to send alert on phone.
Library information
These information are written in the cWB user_parameters files
version: analysis version
version_wat: library wat version
search: cWB search type
optim: user of SRA or MRA
gracedb
For significative triggers, the information are send to gracedb.
gracedb_group: destination (Burst/Test)
gracedb_analysys: cWB
gracedb_search: Allsky
Injections
If injections have been produced, these parameters set where to find information and where to put working directory
inj_name=[]: type of Hardware injection to flag (BURST, CBC, …)
inj_bitmask=[]: bitmask related to Hardware injections
Threshold
Post-production thresholds:
id_rho: choice of rho[0] or rho[1] for event significance
th_rho_off/th_far_off: rho/far threshold for considering offline significant
th_rho_lum: rho threshold for considering to send to gracedb
id_cc: choice of netcc[0] or netcc[1] for event selection
th_cc: netcc threshold
th_qveto: threshold on qveto
Cuts_file: .hh file which contains the list of pp classes
Cuts_list=[]: list of classes for the classification of events
Cuts_name=[]: legends for the list of class to be eventually reported in the web page (not necessary)
Flowcharts
General Analysis
The pipeline considers from the coincidence time from the various detector and then on this it applies the zero lag and the background analyses. If the False Alarm Rate is lower than a threshold set in Configuration file, then the trigger informations are sent to GraceDB. FAR is estimated using the Background analysis as a reference.

Detectors have their proper Data Quality (DQ) times where the analysis can be performed.<br> The analysis consider the coincidence between the various detectors and consider only the segments which has lenght greater than the minimum value in Configuration file

Data arrived in chuncks of usual 4s (frame update). As soon as the data arrives, the pipeline check for coincidences. When coincidence has enough coincidence time (Minimum time in Configuration file), the first job is performed. Then, the pipeline waits for a minor time of coincidence data (Moving time in Configuration file) and perform a job with an overlap with the previous one.
The Summary jobs are updated once the last job is finished and a new small time has been analyzed.
In this way the same trigger can be found more times in different job. In case the same trigger is found multiple time, the one with lower FAR is reported in the Summary.

How to run
There is a script that create all the working directories and the related path for the web pages.
Create Working Directory
First of all create a configuration file for online (config_file in this example). If you do not have an example you can copy the standard one using the command:
cwb_online file config_file
Then change appropriately the configuration file according to the desire of the analysis. Remind to change the working dir.
Then use the command:
cwb_online create config_file
The dir RUN_cWB/config should contain all the files used as configuration:
user_parameters.C: cWB file for zero lag
user_parameters_bkg.C: cWB file for background
user_parameters_bkg_split.C: cWB file for application of superlags in the background
user_pparameters.C: cWB file for standard postproduction web pages
…
The automatic procedure put the same values parameters in all cWB user_parameters files, except for the obvious differences. Typical expected differences are:
diff user_parameters.C user_parameters_bkg.C
13,14c13,17 < lagSize = 1; < lagOff = 0; --- > lagSize = 201; // number of lags (simulation=1) > lagStep = 1.; // time interval between lags [sec] > lagOff = 0; // first lag id (lagOff=0 - include zero lag ) > lagMax = 0; // 0/>0 - standard/extended lags > lagFile = NULL; // lag file list 17c20 < segLen = 60; --- > segLen = 600;
Note: usually background are made on jobs of duration 600 s.
Run zero lag
The script run.py in the RUN_cWB directory makes the zero lag analysis, in particular (names in italic are variable of cWB_conf.py file):
Check the frames present in the online_dir directory
Launch cWB analysis each job_timeout, if not already done in jobs_dir.
Check trigger and send to gracedb the ones with enough significance
If more offsets are requested, the run.py command should be performed in each OFFSET_* directory, where as the same script in RUN_cWB directory merges the triggers coming from the different analyses, eventually checking if the same triggers coming from various analyses, to be considered only once.
All the scripts are launched by crontab in the RUN_cWB directory:
crontab run.crontab
CED are produced automatically in the zero lag analysis.
The collection of figures are made by the script web_pages.py, which produces same figures for various time periods, according to the given value:
daily: each day
hour: last hour
mid: last 12 hours
day: last day
week: last week
run: complete run
all: all the possible solution
These are launched by another crontab script:
crontab web.crontab
The same scripts launch the corresponding figures for background.
Run time shifts
Background is run on dedicated machines, for instance at CIT the ones satisfying the following requirements:
condor_status -constraint TARGET.online_Burst_cWB
Name OpSys Arch State Activity LoadAv Mem ActvtyTime
slot4@node1.cluste LINUX X86_64 Claimed Busy 1.080 3829 0+01:16:52
slot4@node10.clust LINUX X86_64 Claimed Busy 1.120 3829 0+03:58:01
slot4@node2.cluste LINUX X86_64 Claimed Busy 1.090 3829 0+02:33:58
slot4@node3.cluste LINUX X86_64 Claimed Busy 1.070 3829 0+03:43:11
slot4@node4.cluste LINUX X86_64 Claimed Busy 1.100 3829 0+03:28:32
slot4@node5.cluste LINUX X86_64 Claimed Busy 0.140 3829 0+00:31:59
slot4@node6.cluste LINUX X86_64 Claimed Busy 1.140 3829 0+02:22:15
slot4@node7.cluste LINUX X86_64 Claimed Busy 1.050 3829 0+04:26:10
slot4@node8.cluste LINUX X86_64 Claimed Busy 1.050 3829 0+01:41:54
slot4@node9.cluste LINUX X86_64 Claimed Busy 1.100 3829 0+03:05:21
Total Owner Claimed Unclaimed Matched Preempting Backfill
X86_64/LINUX 10 0 10 0 0 0 0
Total 10 0 10 0 0 0 0
To launch background enter in TIME_SHIFTS directory and use the command:
./run_all.sh
Figures are already produced during the web pages production, in any case to update, enter in the directory TIME_SHIFTS/POSTPRODUCTION and launch:
./restart_last_N.sh .
Figures of merit
Results from online are collected in a wiki page with a simple structure:
Status: which contains:
uptime: running time of the whole run
hostname: running machine of zero lag
Page generation: GPS time of the page creation (referred to the calendar)
Tab menu with pages reporting results collected in following periods
last hour
last 12 hours
last day
last week
the whole run
Calendar (collection of pages for each day)
The pages referred in Tab menu shows all the same structure according to different situations:
No jobs during the selected period: a table reporting the start and stop of the considered period.
No triggers during the selected period: a table reporting run statistic (running time, analized segments, …)
Triggers: same table as previous case, information and FOM on the triggers.
We show an example for each table and figure.
Run statistic table

Information about jobs:
Number of completed jobs:
2815: number of zero lag jobs, with link of the time list
Analized segments: time periods after data quality selection
More details: A web page reporting histograms and table of running times, and time delay between arrival data and starting job.
Job run time: Maximum, minimum and average running time for the zero lag jobs
Jobs completed within 10 minutes: percentage of zero lags jobs completed within 10 minutes.
Trigger table

Link reporting:
All trigges without any post-production threshold
Triggers send to gracedb (netcc > cc_th & rho > rho_th (4.0 in the figure))
Triggers considered as GW candidates for a certain rho threshold (5.0 in the figure)
Hardware injections information (if available)
Standard cWB page for zero lag and background.
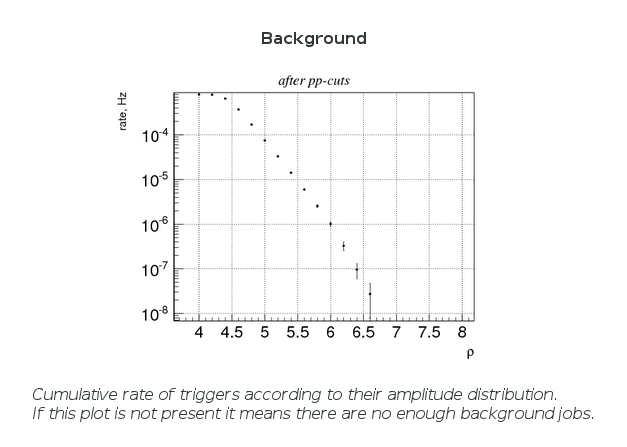
Figure of merits
All of these figures are produced by the standard cWB procedure for web page production: post-production